详细拆解longBlog自动化流程
本文详细拆解了基于Trilium知识库的博客自动化发布流程,从Trilium标签触发、webhook通知、服务器端runner调度,到内容同步、数据生成和Git推送,最终实现自动部署。文章以接近“保姆级”的方式,逐步讲解每个环节的角色与职责,帮助读者理解并复现整个自动化链路。
这篇文章的目标非常直接:
把
longBlog这套自动化流,从“它能跑”讲到“你能看懂”,再讲到“你能在新服务器上复现”。
如果你对 webhook、runner、systemd、Git 自动推送、Trilium 脚本这些概念还比较模糊,也没关系。我会尽量用一种接近“保姆级拆解”的方式来讲。
一、先别急着看代码,先理解它到底在做什么
这套自动化流,其实就是在解决一个问题:
“我在 Trilium 里改了文章,博客为什么能自动更新?”
把这个问题翻译成流程,就是:
- 你在 Trilium 里改了一篇文章
- Trilium 发现这篇文章需要发布或同步
- Trilium 主动通知服务器
- 服务器收到通知后,开始拉内容、生成数据、提交 Git
- GitHub 仓库有了新提交
- 部署平台检测到仓库变化,自动发布新版本
如果只看一句话,这条链路就是:
Trilium → Webhook → 服务器 Runner → Git Push → 自动部署这就是 longBlog 自动化的骨架。
二、整条链路里到底有哪些角色
为了避免一上来就被脚本吓到,我们先把参与者列出来。
1. Trilium
它不是前台博客,而是:
- 文章编辑后台
- 标签状态管理中心
- 自动化触发起点
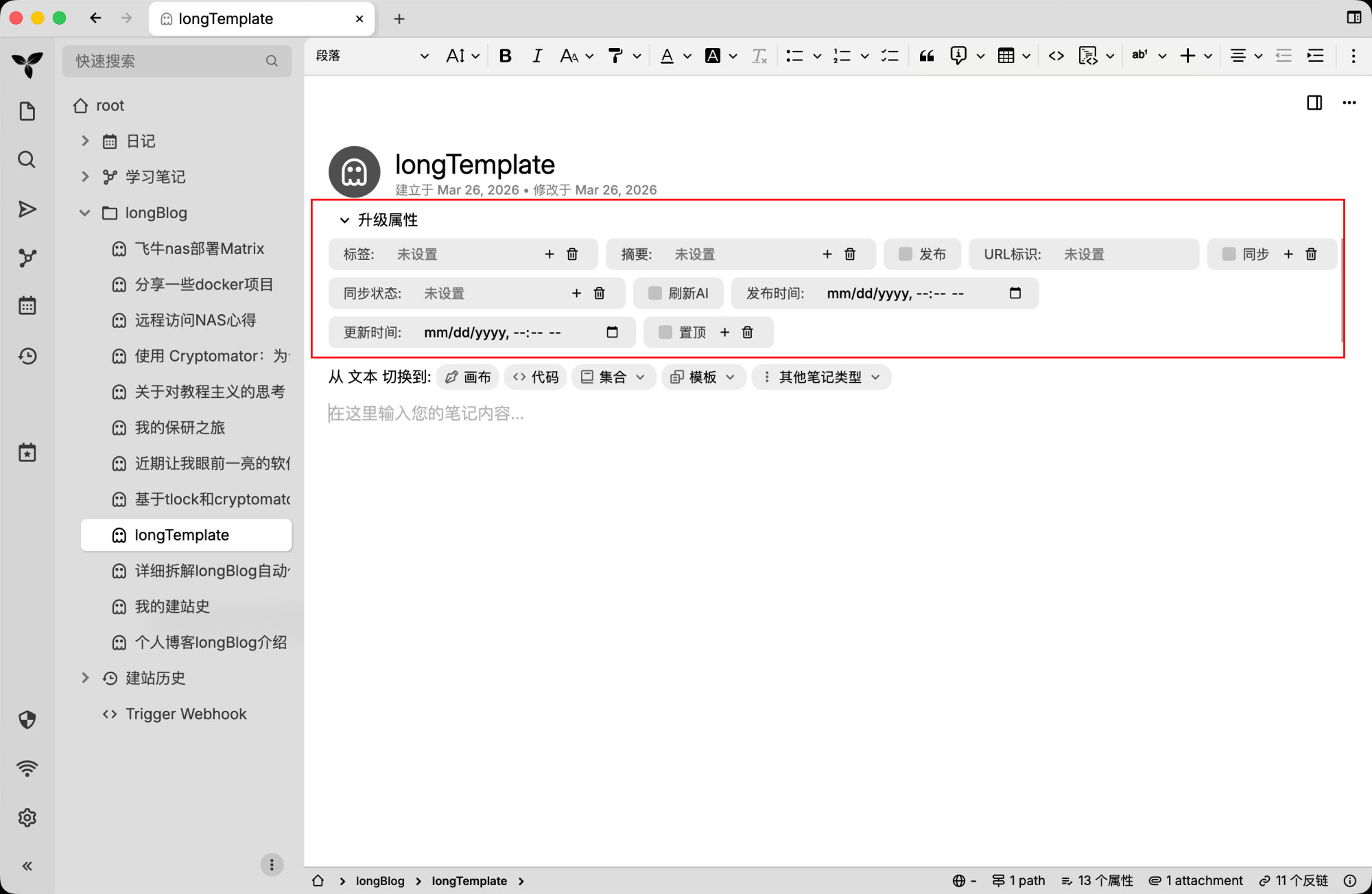
在这里你会给文章打标签,比如:
publish=truesync=truepinned=trueaiRefresh=true
这些标签不是装饰,它们直接决定自动化流怎么走。
2. Trilium 内部 JS 脚本
这是放在 Trilium 里的属性变更脚本,作用是:
- 监听某些标签变化
- 发现变化后,向服务器发送 webhook
也就是说,它相当于“前哨”。
它不负责真正同步内容,只负责说一句:
“服务器,你该干活了。”
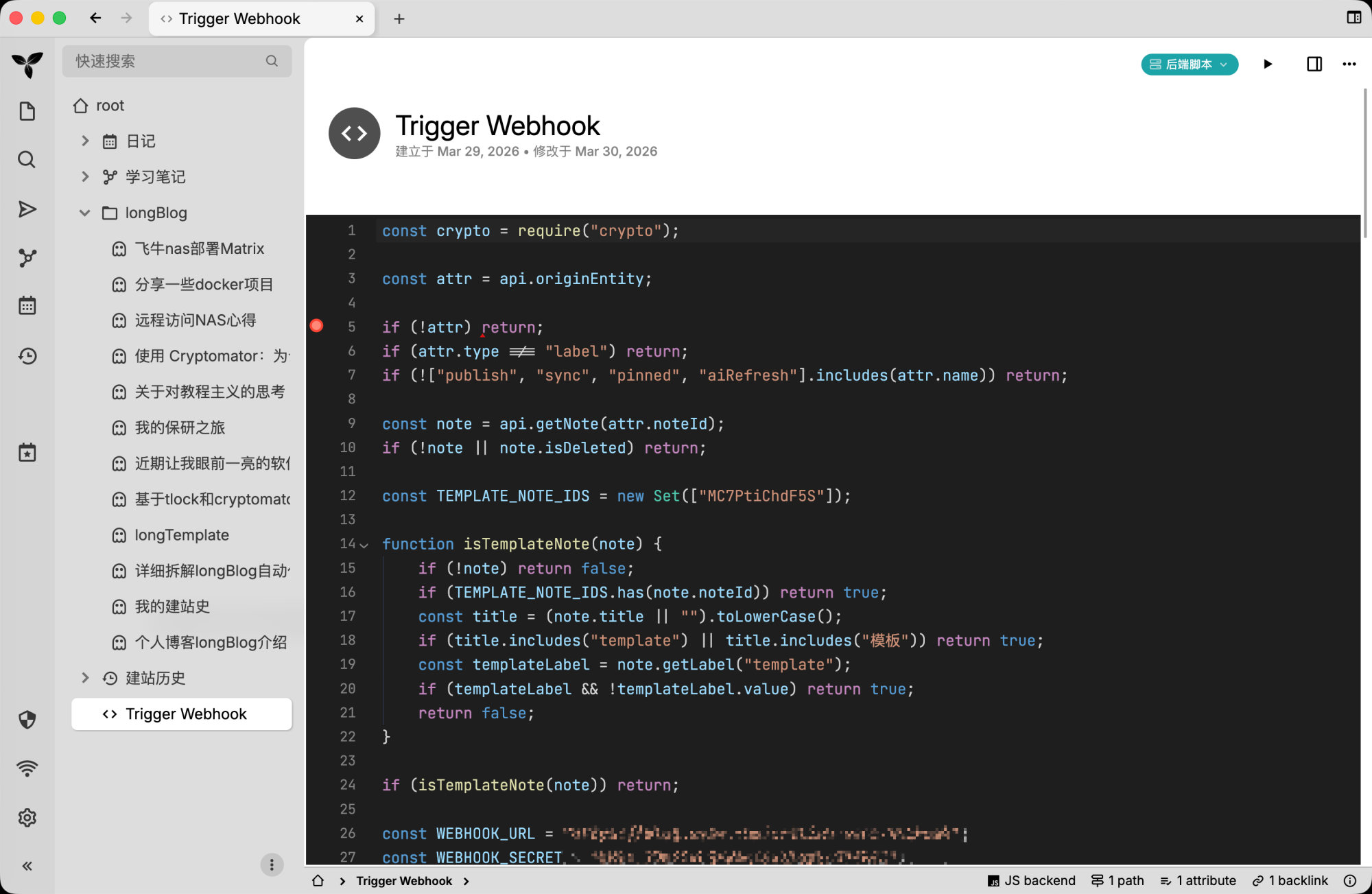
3. 服务器上的 webhook 服务
服务器侧真正接收请求的是一个 Python 脚本服务。
它的作用是:
- 接收来自 Trilium 的 webhook
- 校验签名,防止伪造请求
- 把本次事件记下来
- 拉起 runner
你可以把它理解成“门卫 + 调度通知员”。
4. Runner
Runner 是真正的调度入口。
它负责:
- 防止并发冲突
- 准备工作区
- 调用同步脚本
- 判断有没有 Git 变化
- 决定是否构建验证
- 记录日志和报告
如果 webhook 服务是“通知员”,那 runner 就是“总调度”。
5. 同步脚本
同步脚本才是真正做内容工作的地方。
它负责:
- 从 Trilium ETAPI 拉文章
- 拉附件
- 生成前端数据文件
- 回写文章状态标签
- 在需要时自动 commit / push
这一层才是真正把“知识库内容”翻译成“博客前台可消费数据”的地方。
6. GitHub 仓库
它在这条链路中的作用不是“写文章”,而是:
- 作为前端项目的版本中心
- 作为部署平台的触发源
7. 部署平台
比如 EdgeOne Pages。
它的工作很单纯:
- 发现仓库有新提交
- 拉代码
- 构建
- 发布
也就是说,部署平台并不知道 Trilium、webhook、runner,它只知道:
GitHub 仓库更新了。
三、真正的目录结构应该怎么理解
现在推荐的服务器目录结构是:
/root/longblog-automation/
├── service/
├── runtime/
├── workspace/
│ └── current/
└── check.sh这个结构非常重要,因为很多人第一次做自动化时,最容易犯的错就是:
把服务脚本、运行态、项目源码全部混在一个目录里。
这样后期一定会越来越乱。
所以这里一定要记住三件事:
1. service/
只放服务脚本:
- webhook
- runner
- sync 脚本
它的职责是“执行自动化逻辑”。
2. runtime/
只放运行态:
env.sh- 日志
- 报告
- 状态文件
它的职责是“存运行时产生的信息”。
3. workspace/current/
这是一个独立项目工作区。
它的职责是:
- clone 前端仓库
- 生成数据文件
- 本地化附件
- 构建验证
- Git push
它不是服务本体,而是“runner 干活的地方”。
这一点一定要分清。
四、具体流程:从 Trilium 改一篇文章开始
我用一个最常见的例子:
场景:你给某篇文章打上 sync=true
下面是这条链路实际发生的事情。
第一步:Trilium 内部脚本监听到标签变化
Trilium 脚本发现:
- 某篇 note 的
sync标签变成了true
于是它会构造一个 webhook 请求体,大概长这样:
{
"event": "sync_requested",
"requestId": "noteId-sync-时间戳",
"noteId": "某篇文章的 noteId",
"noteTitle": "文章标题",
"sync": "true",
"triggeredAt": "触发时间"
}然后脚本会:
- 用 secret 计算 HMAC-SHA256 签名
- 发到服务器的
/trilium-sync-webhook
也就是说:
Trilium 不是“等待服务器轮询”,而是“主动通知服务器”。
第二步:服务器 webhook 服务接收请求
服务器入口收到请求后,会先做两件事:
1. 校验签名
确保这不是别人伪造的 webhook。
2. 校验 payload
确保:
event是合法事件noteId存在sync=true这种字段值也合理
如果这些都没问题,它才会继续。
然后它会把这次请求记下来,再拉起 runner。
第三步:Runner 被启动
Runner 启动后先做一件非常关键的事:加锁
为什么要加锁?
因为 webhook 有可能很密集,比如:
- 你刚改完
publish - 又改了
pinned - 又手动点了
sync
如果这些请求同时跑,很容易把工作区搞乱。
所以 runner 会先建立一个锁:
- 如果当前没有人在跑,就开始执行
- 如果已经有实例在跑,就记一个“补跑标记”
这一步就是为了避免并发踩踏。
第四步:Runner 准备工作区
Runner 会去准备:
/root/longblog-automation/workspace/current
这里会做:
- clone 仓库(如果第一次运行)
- 或 fetch 最新远端
- reset 到远端最新状态
你可以把它理解成:
“先把前端项目工作台摆好,再开始干活。”
第五步:调用同步脚本
同步脚本启动后,会做很多真正的业务动作。它会先扫描 Trilium 根节点
根节点下面不一定全是文章,所以它会过滤:
- 根节点本身
- 模板 note
- 非文章 note
- 特定应跳过的 note
然后识别哪些文章应该发布
如果某篇文章:
publish=true
它就会进入发布候选。
如果某篇文章:
publish=false
而之前又已经发布过,那它会进入“撤下”逻辑。
第六步:读取文章正文与附件
对每篇候选文章,同步脚本会:
- 拉取 HTML 正文
- 提取里面引用的附件 URL
- 下载附件
- 保存到:
public/trilium-assets/<noteId>/...
这样前端页面就不必直接依赖 Trilium 附件地址,而是能用本地化后的静态资源。
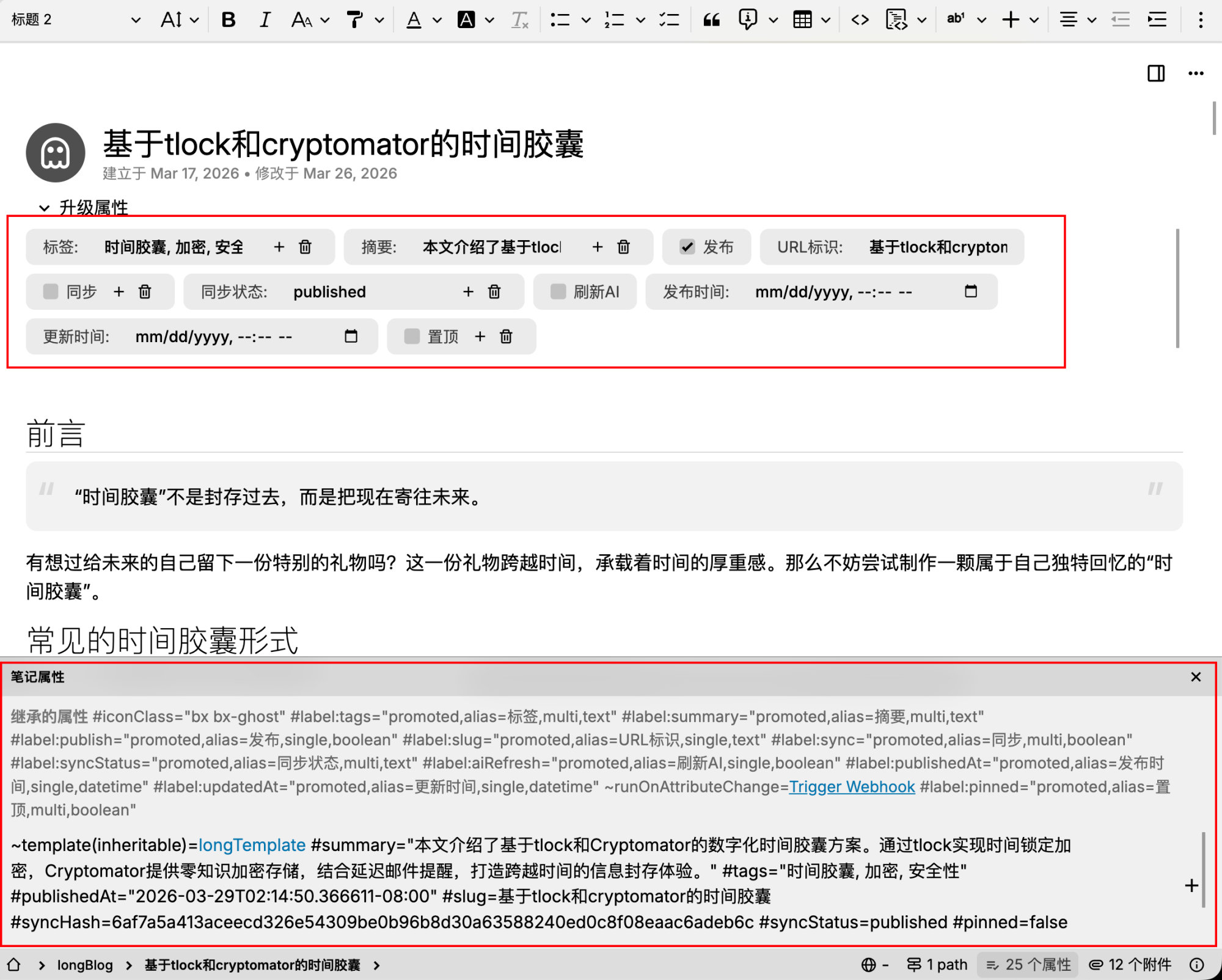
第七步:生成前端数据文件
这一步是整个自动化流最核心的一步。
同步脚本最终会生成:
1. trilium-posts.content.generated.ts
里面放:
- 标题
- 摘要
- HTML 正文
2. trilium-posts.meta.generated.ts
里面放:
- slug
- 更新时间
- 发布时间
- 标签
- 置顶状态
- syncHash
- syncStatus
前端页面并不会直接调 Trilium ETAPI,而是消费这两份生成文件。
这就是“知识库内容 → 前端静态数据”的桥梁。
第八步:回写 Trilium 标签
同步脚本不仅会读 Trilium,也会回写状态。
例如:
slugsummarytagspublishedAtupdatedAtsyncHashsyncStatussync=falseaiRefresh=false
为什么要回写?
因为你希望 Trilium 本身也知道:
- 这篇文章现在是什么状态
- 它有没有发布成功
- 它的摘要 / slug 是什么
否则状态就会分裂:
- 博客一套
- 知识库一套
那后面一定会越来越难维护。
第九步:判断 Git 是否真的有变化
这一步很重要。
自动化流不是每次都应该 push。
如果这次同步结果和现有文件完全一样,那就应该:
gitChanged=falsegitPushed=falsebuildRan=false
这是为了避免:
- 无意义提交
- 无意义部署
- 外部平台被白白唤醒
现在这套链路已经收敛到这个方向了。
第十步:有变化才 commit / push
如果确实有变化,才会:
git addgit commitgit push origin main
这一步推上 GitHub 后,部署平台就会开始感知到仓库更新。
第十一步:可选 build 验证
如果 gitChanged=true,runner 还会视情况执行:
npm installnpm run build
但这里一定要理解清楚:
服务器上的 build 不是正式发布源,而是“构建验证”。
真正正式发布的仍然是:
- GitHub 仓库
- 部署平台自动拉取并构建
五、为什么要把服务目录和工作区分开
这是整个系统最容易理解错的地方,我单独讲一次。
旧思路:所有东西都塞进一个 /root/longBlog
这样做的问题是:
- 你分不清哪些是服务脚本
- 哪些是工作区产物
- 哪些是 runtime 日志
- 哪些只是构建缓存
时间一长一定乱。
新思路:三层分离
service/负责执行逻辑。
runtime/负责记录运行态。
workspace/current/负责项目工作区。
这样以后你看一眼目录就知道:
- 服务在哪里
- 日志在哪里
- 工作区在哪里
对于迁移服务器尤其重要。
六、如何在新服务器上重新部署这套自动化
下面这一段,是你真的可以照着做的部分。
第一步:装基础环境
如果是 Debian / Ubuntu,先装:
apt update
apt install -y git python3 python3-pip nodejs npm nginx curl第二步:创建目录
mkdir -p /root/longblog-automation/service
mkdir -p /root/longblog-automation/runtime/logs
mkdir -p /root/longblog-automation/runtime/reports
mkdir -p /root/longblog-automation/runtime/state
mkdir -p /root/longblog-automation/workspace第三步:放入服务脚本
把这些文件放到:
service/trilium_sync_webhook.pyservice/run_sync_and_build.shservice/sync_trilium_posts.py
如果你已经有对应模板仓库,直接从模板仓库复制即可。
第四步:写 runtime/env.sh
这个文件最重要,因为它决定自动化能否真正运行。
你至少要配置:
TRILIUM_BASE_URLTRILIUM_ETAPI_TOKENTRILIUM_BLOG_ROOT_NOTE_IDTRILIUM_PUBLISH_WEBHOOK_SECRETDEEPSEEK_API_KEYLONGBLOG_RUNTIME_DIRLONGBLOG_REPO_DIR
然后:
chmod 600 /root/longblog-automation/runtime/env.sh第五步:准备工作区
cd /root/longblog-automation/workspace
git clone git@github.com:YOUR_ORG/YOUR_REPO.git current并确保服务器 SSH key 有权限访问这个仓库。
第六步:配置 systemd
把 longblog-webhook.service 放到:
/etc/systemd/system/longblog-webhook.service
然后执行:
systemctl daemon-reload
systemctl enable longblog-webhook.service
systemctl start longblog-webhook.service第七步:配置 Nginx
为 /trilium-sync-webhook 配一条反代:
location /trilium-sync-webhook {
proxy_pass http://127.0.0.1:8787/trilium-sync-webhook;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}然后:
nginx -t && systemctl reload nginx第八步:恢复 Trilium 里的 JS 脚本
这是很多人迁移时最容易漏掉的一步。
如果你只恢复了服务器,却没恢复 Trilium 里的属性变更脚本,那么:
- 服务器永远收不到 webhook
- 自动化也就永远不会触发
所以一定要把 Trilium 侧脚本也恢复。
并且替换:
WEBHOOK_URLWEBHOOK_SECRET
确保和服务器一致。
第九步:先做巡检,再做真实测试
如果你有巡检脚本,比如:
/root/longblog-automation/check.sh那先跑它。
你至少要看到:
- systemd 服务是 active
- 8787 在监听
- runtime 路径正常
- workspace 路径正常
然后再在 Trilium 里手动测试一篇文章:
sync=true
最后观察:
trilium_sync_webhook.loglast_report.jsonsync.logbuild.log
如果这里都通了,整条链路基本就通了。
七、这套自动化最容易踩的坑
1. 只恢复服务器,不恢复 Trilium 脚本
结果:根本不会触发自动化。
2. 服务目录、工作区、runtime 混在一起
结果:越跑越乱,迁移时根本不知道该搬什么。
3. 没有做并发锁
结果:多个 webhook 同时跑,把工作区搞乱。
4. 无变化也 commit / push
结果:部署平台反复无意义触发。
5. 把真实 secret 提交到 Git
结果:后患无穷。
八、总结
如果要把这篇文章最后压缩成一句话,我会这么说:
这套自动化流,就是让 Trilium 里的标签变化,自动变成博客仓库里的可部署更新。
而实现它的关键,并不只是脚本本身,而是你要把下面这几层一起理顺:
- Trilium 触发脚本
- 服务器 webhook 服务
- runner 调度
- 工作区同步
- Git push
- 部署平台发布
当你真正把这几层分清楚之后,你会发现它没有看起来那么神秘。甚至你完全可以在一台新服务器上,把它重新搭起来。这就是这套自动化流最有价值的地方。